First of all, you have to put the header definitions into the right header file (i.e. DBFileTypes_X.txt) where X defines the header version of the underlying DB file.
You don't need to change any source code to add support for new files. That was part of the main idea 
Most DB files have the following layout:
4 bytes header
2 bytes GUID length
72 bytes GUID
4 bytes old header
4 byte header version (unsigned integer)
1 byte end of header flag
4 byte number of data entries
eof - 91 byte data entries
all other layouts are considered as header version 0
That was the easy part.
Now you have to analyse the individual db files. You will need a hex editor and try to find the recurring scheme within the files.
A simple example:
You'll quickly notice this file has header version 0. The four bytes starting at 0x4F (i.e. 03 00 00 00) tell you that there are three entries in this file and a quick look at the data following 0x53 (on the right side) show you that these three entries are simple strings.
The correct entry in DBFileTypes_0.txt would therefore look like this:
cai_agent_recruitment_types[TAB]unknown,string
Now a more complex example:
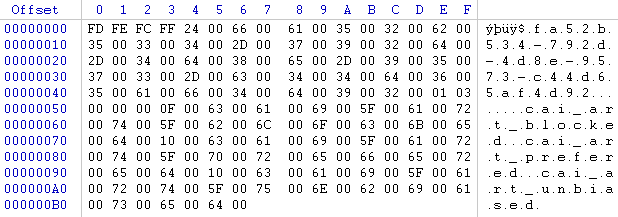
Here, the four bytes at 0x52 tell you that the header version is 2 and one byte later, you learn that there are 24 entries (i.e. 18 00 00 00) in this file.
With a bit of practise, you'll quickly see that the traits are stored as strings and are followed by an index (i.e. the number increases with every entry).
The correct entry in DBFileTypes_2.txt would therefore look like this:
avatar_traits[TAB]Trait IDRef,String;
Index,UInt32
Nota bene: If there is a semicolon at the end of a line, the next line will also be parsed!
Finally, a word on data types. CA used only a limited number of types:
UInt32: e.g. 03 00 00 00
Single: e.g. 00 00 40 41 or 9A 99 99 3F
Boolean: 01 or 00
String: Any text (will always have two extra bytes for the string length in front of and is coded in UTF-8) e.g. "avatar" would be 06 00 61 00 76 00 61 00 74 00 61 00 72 00, where 06 00 is the length.
I hope little guide helped to clarify the basics of adding new db files to PFM.
If you have any questions, please feel free to ask.



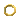
 Reply With Quote
Reply With Quote